
Le budget d’exploration (crawl budget) d’un site est un sujet souvent discuté dans la communauté, mais rarement abordé en profondeur. Pourtant, tous sites internet, grands et petits, peuvent grandement bénéficier d’un budget d’exploration augmenté.
En analysant le comportement de Googlebot et en lui facilitant le travail, vous pouvez gagner un indéniable avantage sur votre compétition.
L’article d’aujourd’hui portera sur la compréhension du budget d’exploration et des stratégies pour le maximiser.
Comment fonctionne les robots d’exploration
Avant de parler de budget d’exploration, commençons à la base avec un rappel sur le fonctionnement des robots d’exploration. Leur principale tâche est de découvrir les pages web accessibles au public, et de renvoyer les informations pertinentes aux serveurs de Google.
Le processus débute par une liste des URL d’un site, obtenues soient par une visite précédente, ou encore via un fichier sitemap.xml. Cela peut également être une URL partagée en ligne, ou un lien entrant pointant vers un nouveau contenu.
Dans tous les cas, les robots d’exploration vont suivre tous les liens internes et externes à partir de la page explorée par le robot, dans l’optique de découvrir les nouveaux contenus ou ceux ayant changés dernièrement.
Qu’est-ce que le budget d’exploration ?
Le budget d’exploration (crawl budget) se définit par le nombre de pages et/ou le nombre de temps que Googlebot décide de consacrer à votre site. On peut comparer le budget d’exploration à un degré d’attention, ou encore de ressources, que les robots d’exploration accordent à votre site.
Google aborde très peu le sujet du budget d’exploration dans sa documentation en ligne. Possiblement l’extrait le plus révélateur sur le fonctionnement du budget d’exploration remonte déjà à quelques années lors d’une interview de Matt Cutts:
« There is also not a hard limit on our crawl. The best way to think about it is that the number of pages that we crawl is roughly proportional to your PageRank. So if you have a lot of incoming links on your root page, we’ll definitely crawl that. Then your root page may link to other pages, and those will get PageRank and we’ll crawl those as well. As you get deeper and deeper in your site, however, PageRank tends to decline.
Another way to think about it is that the low PageRank pages on your site are competing against a much larger pool of pages with the same or higher PageRank. There are a large number of pages on the web that have very little or close to zero PageRank. The pages that get linked to a lot tend to get discovered and crawled quite quickly. The lower PageRank pages are likely to be crawled not quite as often. »
Si l’on décide de croire Matt Cutts, le budget d’exploration est principalement défini par le degré d’autorité d’un site, soit la qualité de son profil de liens entrants. Plus le site reçoit des liens externes de qualité, plus fréquemment il sera exploré par les robots.
Cela constitue un bon départ, mais il ne faut pas oublier que la puissance du moteur de recherche a grandement évolué depuis les dernières années. Particulièrement suite à la mise à jour Caféine, Google est en effet capable de visiter beaucoup plus de sites et de pages qu’auparavant :
« With Caffeine, we analyze the web in small portions and update our search index on a continuous basis, globally. As we find new pages, or new information on existing pages, we can add these straight to the index. That means you can find fresher information than ever before—no matter when or where it was published. »
Ce qu’il est important de comprendre, n’est pas nécessairement que la mise à jour Caféine permet d’indexer plus de contenu de profondeur, mais qu’on priorise le contenu récent et à jour. Google souhaite donc que les pages importantes soient indexées en priorité au sein de son index.
Si on veut donc maximiser son budget d’exploration, il faut donc s’assurer que les pages les plus récentes et importantes de votre site soient faciles à explorer pour les robots d’exploration.
Connaître son budget d’exploration
La question suivant la lecture des précédents paragraphes sera probablement la suivante : comment puis je déterminer le budget d’exploration présentement alloué à mon site ?
Malheureusement et comme nous le mentionnions plus tôt, Google ne partage pas de chiffres précis ni d’explications sur le calcul du budget d’exploration.
Heureusement, il est très facile d’estimer le budget d’exploration présentement accordé à votre site, en consultant les données d’exploration contenues dans la plateforme Google Search Console.
En effet, en accédant au rapport « Statistiques d’exploration », on peut savoir le nombre de pages que Google explore en moyenne sur votre site, par jour :
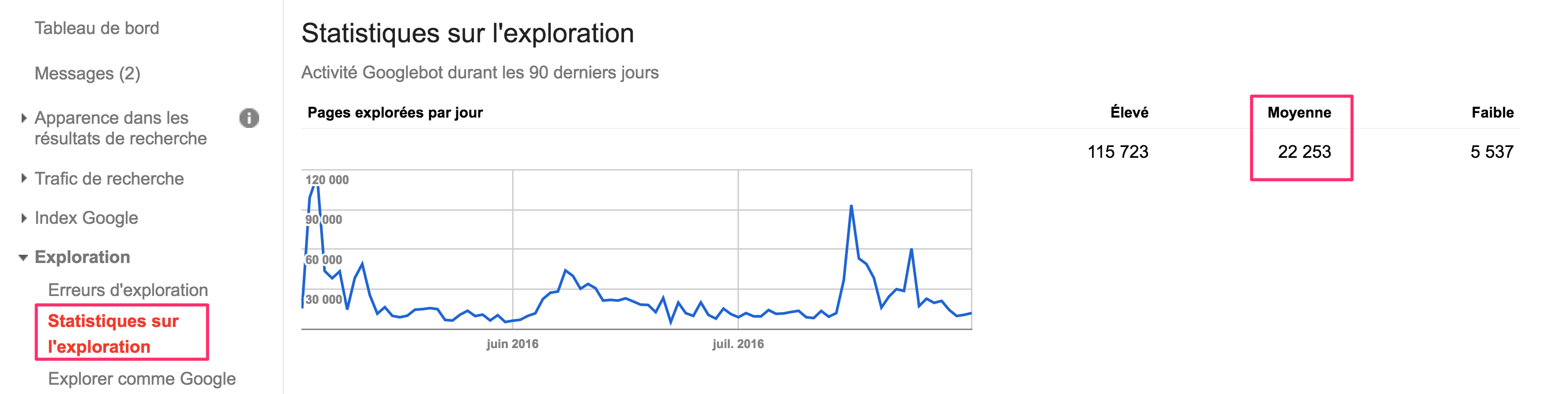
Ainsi, Google a exploré en moyenne 22 253 pages par jour durant les trois derniers mois. Le budget d’exploration mensuel de mon site est donc de 667 590. Ce calcul n’a rien de scientifique et probablement que d’autres méthodes existent (par exemple avec les fichiers de serveur log) mais en ce qui me concerne, ce calcul est rapide et suffisamment précis.
Le plus important n’est pas uniquement de savoir le nombre de pages que Google explore sur votre site, mais surtout si ce nombre augmente et/ou diminue. Comme nous le verrons dans la section suivante, il est possible d’augmenter le nombre de pages explorées sur votre site en optimisant certains facteurs pouvant influencer positivement votre budget d’exploration.
9 conseils pour optimiser le budget d’exploration
Il existe plusieurs stratégies visant à maximiser votre budget d’exploration. La plupart sont des tactiques SEO de longue date, et n’auront rien de nouveau pour la plupart des lecteurs de cet article. Par contre, plus votre site est volumineux, plus vous pouvez toujours améliorer votre budget d’exploration.
Voici une liste d’actions à vérifier et/ou implanter dès maintenant.
#1 – Assurer l’indexation de vos pages les plus importantes
La première règle consiste bien sûr à vous assurer que les pages les plus importantes de votre site sont parfaitement accessibles pour les robots d’exploration. En d’autres termes, celles-ci ne doivent pas êtres bloquées par le fichier robots.txt ou encore un attribut noindex.
Un bon test consiste à chercher directement dans Google l’URL de vos pages afin de vérifier si celles-ci sont belles et bien indexées.
#2 – Éviter les erreurs d’exploration
Il va sans dire que si vous désirez optimiser et accroître votre budget d’exploration, vous devez éviter que les robots rencontrent des erreurs lors de l’exploration de vos contenus. Cela veut dire bien sûr les erreurs 4XX et 5XX, mais également de faire attention aux redirections.
Même s’il ne s’agit pas d’une erreur d’exploration proprement dit, une redirection 301/302/303 demande plus de ressource à un robot d’exploration qu’une consultation d’une page répondant avec le code « Ok » (200). Ainsi, les robots d’exploration peuvent passer plus de temps à suivre vos redirections qu’à explorer des contenus statiques.
Ce n’est pas un point critique d’avoir quelques redirections sur votre site – cependant dans une optique d’optimisation où la rapidité et la facilité d’exploration compte pour beaucoup, le moins possible sera le mieux.
#3 – Opter pour une cure minceur
Ce point a été abondamment discuté suite à l’avènement de la mise à jour du Panda il y a (déjà!) plusieurs années. Si on souhaite augmenter le budget d’exploration, il devient logique d’éviter de présenter des pages ayant peu de valeur.
D’ailleurs, un des fondements même de l’optimisation d’un site pour contrer le Panda est de vérifier que ses contenus ont des fortes statistiques d’engagement, ainsi qu’une raison d’être.
Si vous avez des pages dont l’indexation vous laisse indifférent, ou encore deux pages qui se battent pour les mêmes mots-clés, une cure minceur s’impose. Cela peut aller à la suppression/redirection de la page ou simplement bloquer celle-ci dans le robots.txt.
#4 – Améliorer la vitesse de chargement (en particulier le Gzip)
Lors d’une récente entrevue, Gary Illyes, un ingénieur devenu au fil des dernières années l’un des porte-parole officiels de Google, mentionnait que Googlebot continuera à explorer un site à moins que le serveur du site ralentisse la progression du robot d’exploration :
And once we re-crawl a bucket of URLs, high-importance URLS, then we will just stop. We will probably not go further. Every single…I will say day, but it’s probably not a day…we create a bucket of URLs that we want to crawl from a site, and we fill that bucket with URLS sorted by the signals that we use for scheduling, which is site minutes, PageRank, whatever. And then from the top, we start crawling and crawling. And if we can finish the bucket, fine. If we see that the servers slowed down, then we will stop.
Ainsi, l’exploration des URL prioritaires d’un site peut être affectée par une contre-performance du serveur. Il devient donc logique d’optimiser au maximum la vitesse de chargement, non seulement pour les visiteurs, mais aussi pour faciliter l’exploration de la liste d’URL de votre site par les robots.
L’un des principaux gains au niveau de la vitesse de chargement est sans contredit la compression GZIP, qui peut réduire jusqu’à 70% de la taille de vos fichiers.
#5 – Assurer la propreté du sitemap.xml
Au cours de la même entrevue, Gary Illyes déclare également que Googlebot accorde généralement une importance élevée aux URL contenues dans le fichier sitemap :
I think what you are talking about is actually scheduling. Basically how many pages do we ask from indexing side to be crawled by Googlebot? That’s driven mainly by the importance of the pages on a site, not by number of URLs or how many URLs we want to crawl. It doesn’t have anything to do with host-load. It’s more like, if…this is just an example…but for example, if this URL is in a sitemap, then we will probably want to crawl it sooner or more often because you deem that page more important by putting it sitemap.
We can also learn that this might not be true when sitemaps are automatically generated. Like, for every single URL, there is a URL entering the sitemap. And then we’ll use other signals. For example, high PageRank URLs…and now I did want to say PageRank…probably should be crawled more often. And we have a bunch of other signals that we use that I will not say, but basically the more important the URL is, the more often it will be re-crawled.
Cela signifie que vous devez un fichier sitemap.xml propre et à jour, mais également, ne pas paresseusement ajouter chaque URL de votre site, car si le sitemap contient une liste complète des URL d’un site, Google se tournera vers d’autres facteurs pour établir une priorité au niveau des URL.
Prenez le temps de raffiner votre liste, et d’y ajouter uniquement les URL que vous considérez comme prioritaire pour votre site.
#6 – Éviter les chaînes de redirections
Une chaîne de redirection survient lorsqu’un utilisateur et/ou un robot d’exploration doit passer à travers plusieurs redirections avant d’arriver à la destination finale. À moins de clairement exagérer sur le nombre de redirections, l’impact SEO est généralement faible, mais cela demande tout de même plus d’efforts aux robots d’exploration.
En 2011, Google mentionnait un maximum de 3 redirections consécutives avant que le robot d’exploration n’abandonne sa quête de rejoindre l’URL finale. Maintenant en 2016, Google mentionne qu’un maximum de 5 redirections consécutives est permis.
Quelque soit la limite, de mettre en place une chaîne de redirection est une façon très efficace de gaspiller le temps et les ressources d’exploration qui vous sont accordées.
#7 – Acquérir des liens entrants vers les pages internes
Le PageRank d’un site est intimement lié à son budget d’exploration. Si Google explore plus souvent et rapidement les URL à fort PageRank, cela signifie qu’il faut acquérir des liens entrants de qualité et les pointer vers les pages importantes de votre site.
De plus, comme nous avons vu, les pages explorées les plus fréquemment sont aptes à récolter plus de trafic que les pages explorées sporadiquement. Le fait que des liens externes crédibles pointent vers les pages dont vous souhaitez augmenter l’exploration est donc une tactique très importante à considérer.
Cela signifie bien sûr de non seulement diriger les liens externes vers votre page d’accueil, mais aussi vers les pages internes de votre site.
Attention – si vous avez des problèmes techniques sur votre site tels des erreurs d’exploration, fichier sitemap.xml malpropre ou encore des chaînes de redirections, vous devez corriger celles-ci en premier. Sinon, vous devez continuellement travailler sur l’acquisition de liens entrants vers les pages prioritaires de votre site.
#8 – Optimiser la structure de navigation
Non seulement vos pages prioritaires doivent êtres mises de l’avant dans votre structure de navigation, mais vous devez également faire le maximum pour que Google accède à l’ensemble de vos pages avec le minimum de clics.
Cela mène donc à une architecture plus étirée, au lieu que les sections travaillent en silo, par exemple:
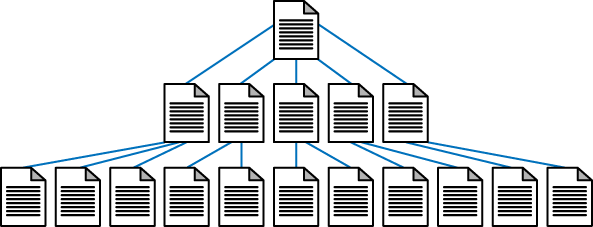
La fameuse règle du « 3 clics depuis la page d’accueil à page secondaire » est loin de faire l’unanimité, car il devient difficile voir impossible de la respecter lorsque l’on travaille sur des sites ultra-volumineux et comportant plusieurs divisions internes.
Cela dit, le point à retenir est que lorsque possible, veiller à raccourcir votre architecture au maximum afin que les robots d’exploration puissent accéder aux pages internes.
D’ailleurs, comment pouvez-vous savoir quelles sont les pages les plus importantes selon votre structure de navigation ? Simplement en accédant à Google Search Console au rapport « Liens internes » (sous trafic de recherche), qui vous indiquera, selon votre structure de navigation les liens jugés les plus importants :

Si votre structure de navigation est optimale, vos liens les plus importants seront en tête de liste. Sinon… vous avez du pain sur la planche 😉
#9 – Gérer les paramètres d’URL
Cette règle vous concerne si vous utilisez un CMS qui génère des URL dynamiques pour vos pages, qui la plupart du temps, génèrent des cas de contenus dupliquées. Le problème est que les robots d’exploration vont gaspiller beaucoup de temps et de ressources à explorer ces URL qui mèneront vers des contenus déjà existants.
Si votre CMS ajoute des paramètres à vos URL, vous devez le faire savoir à Google, par le biais de la plateforme Google Search Console (sous paramètres d’URL).
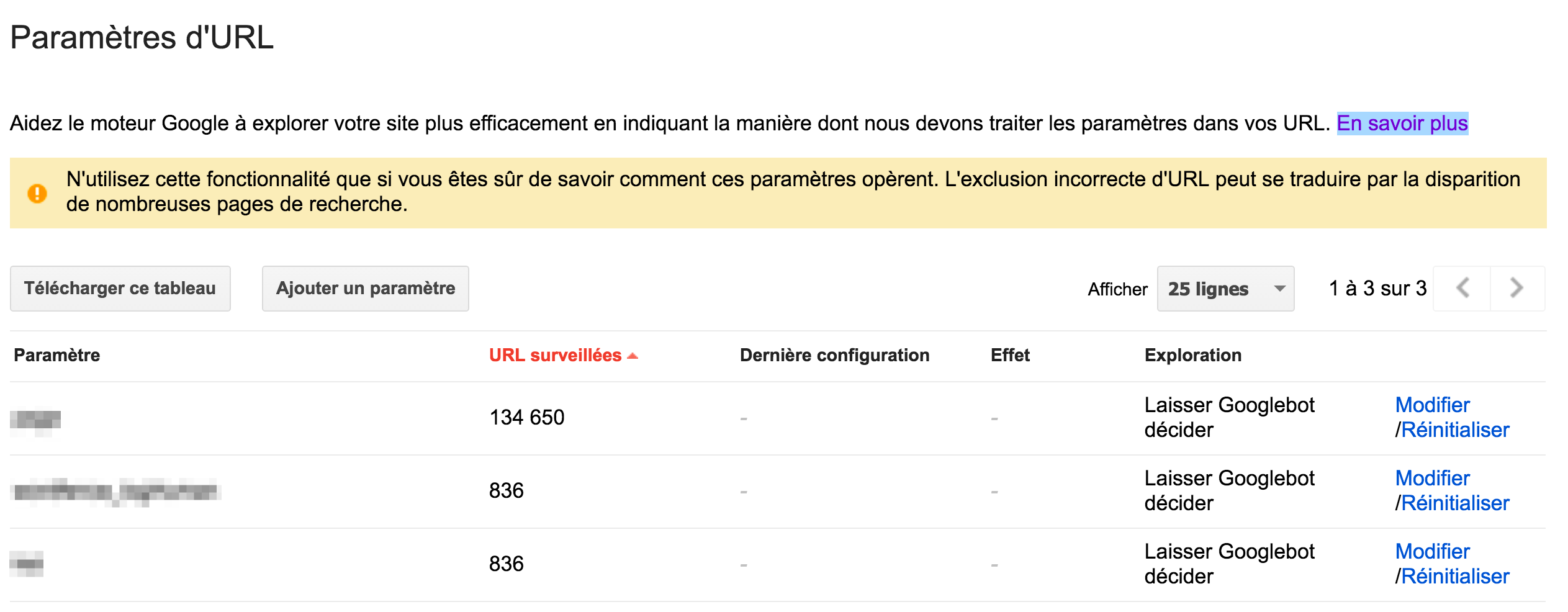
Attention : il faut savoir ce que l’on fait quand on ajuste les paramètres cette fonctionnalité. Ce lien donne d’ailleurs l’essentiel des directives à suivre pour bien utiliser cet outil.
Les résultats auxquels vous pouvez vous attendre
Si vous prenez le temps d’optimiser les éléments mentionnés sur cette liste, vous pourrez être en droit de rapidement constater des améliorations.
J’ai récemment investi beaucoup de temps et d’efforts à optimiser le budget d’exploration d’un projet sur lequel je collabore avec des amis.
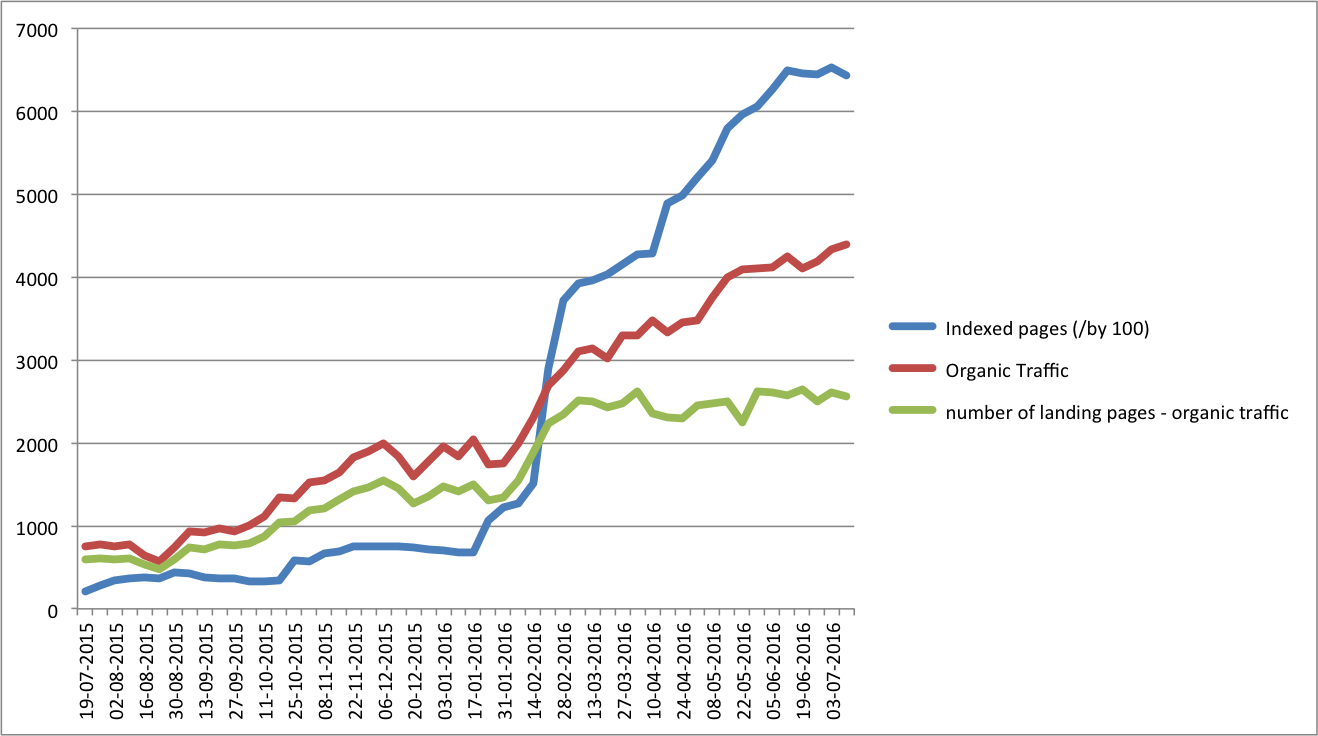
Le constat est simple : plus je travaille à faire explorer et conséquemment indexer des pages, plus le trafic organique suivra la cadence et connaîtra une croissance.
En résumé, la leçon est fort simple: traiter les robots d’exploration comme des partenaires de trafic, et faites le maximum d’efforts pour leur faciliter la tâche. Votre récompense se notera au niveau du trafic organique vous recevrez.


